Pruning
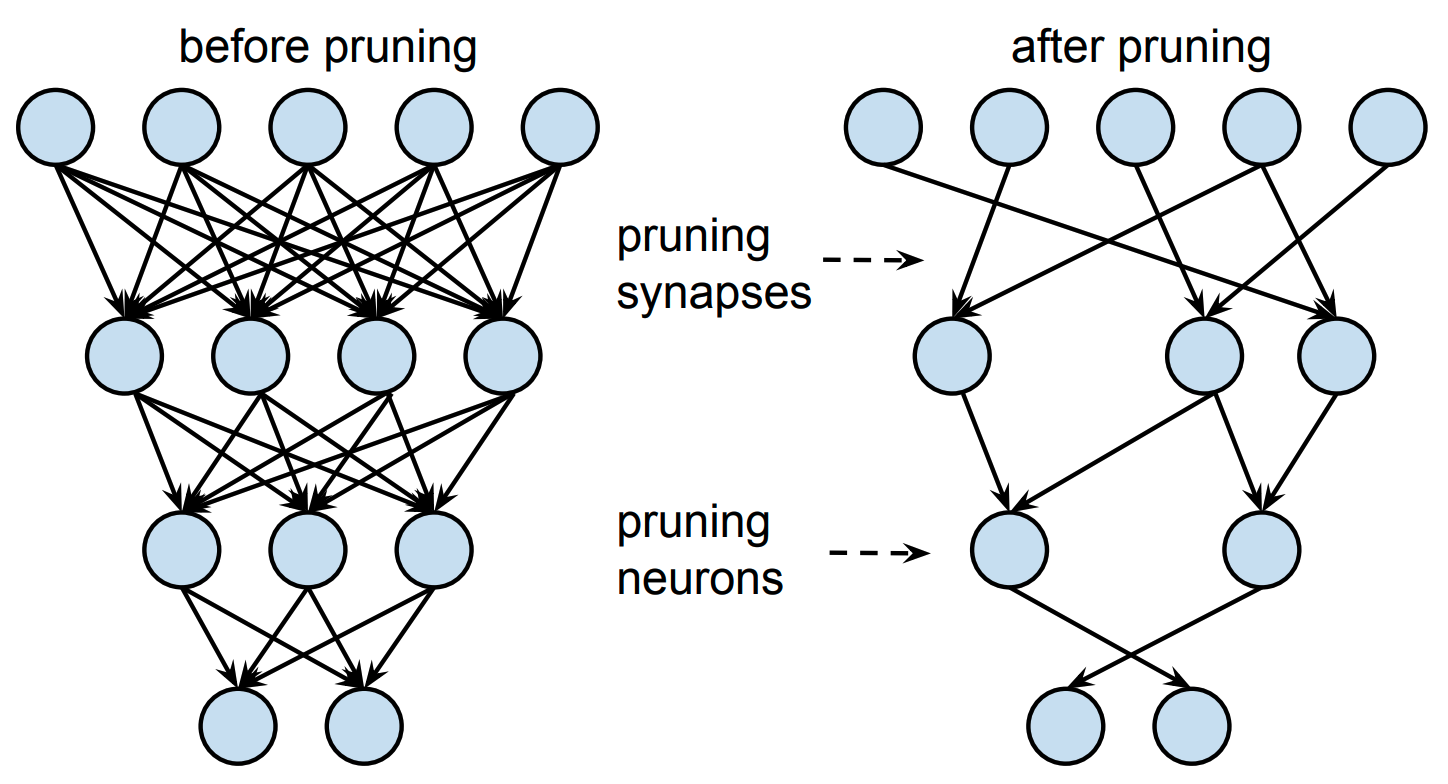 image reference:TDS
image reference:TDS
As we move towards using neural networks for lower constraint devices, one dilemma we constantly face is the size of deep neural networks. Since DNNs were conceputalised to deal with large data they inturn gave rise to larger models.
These models grew larger over time, achieveing greater accuracy and also utilising enormous compute like high performance GPUs. Thus taking the focus from speed and putting to the performance based on accuracy.
With TinyML, adopters quickly realised that such models are not built for real world systems, especially for deployment. Hence the easy and straightforward solution was to cut down or reduce the size of neural networks.
So how do we cut down or prune neural networks?
Neural networks are composed of different parameters: primarily, the weights and neurons. We know that if we reduce these parameters, it would eventually make the network smaller. But does this effect the model in any manner? Yes large neural networks, tend to be more accurate. If we were to prune some of it's parts, then neural networks would loose its accuracy. Hence, our goal is to make pruned networks loose less accuracy and preserve it as close to it's orginal model. This means, we need to systematically reduce parameters throughout the network.
Methods of pruning networks
As mentioned before one of the important parts of a neural network is the weights. Le us see, how do we prune weights in a neural network.
1. Magnitude weight based Pruning
One easy way to reduce the weights is to set it to zero. But you don't want to set weights with higher values to zero. You would rather select weights close to zero and change them to zero. This is known as magnitude weigjht pruning which helps to trim insight weights in the network.
2. Neuron based Pruning
Second way to prune is to make drop neurons from the network. But how do you do this without loosing too much of the accuracy? The first step is to understand the network and neurons present in it. Rank these neurons based on their importance and remove the least imprortant neuron
In both the methods above, it is important to test the model and it's performance, and focus on doing it in an iterative process.
Results: Does this really work?
If we look at at Magntitude weight based Pruning, Tensorflow currently reports a 6x improvements in model compression with minimial loss in accuracy.
They tested their model on Imagenet using InceptionV3 and MobileNetV1 based models:
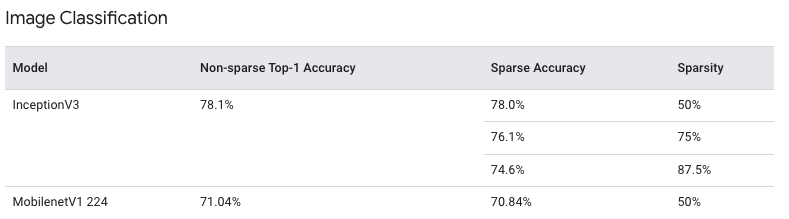
One can notice that even with 87.5% sparsity of networks, which means that 87.5% of the network was pruned, there is only a 2% drop in accuracy. Thus making these models perfect for low resource microcontrollers or compute devices.
Ok I am interested where do I start?
Awesome, if we have got you interested, you can check the steps to Pruning using Tensorflow
Alternatively, you can use the scaledown package and do it in less than 10 lines of code!
Resources
- Towards Data Science: Pruning Neural Networks
- Research Paper: WHAT IS THE STATE OF NEURAL NETWORK PRUNING?
- Wikipedia: Pruning(artificial neural networks)