 Archana
Archana 
Quantization
Definition of Quantization:
When we look at signal processing, quantization orginally means the process of mapping input values to a large set of output values in a smaller set, with a finite number of elements.
But as we look at edge computing Quantization is the process of reducing higher floating bit values like FP-32, FP-64 to lower bit precision values like int8 while making sure we preserve the information in the neural networks
But why do we need Quantization?
Need for Quantization
When we look at Deep Neural Networks, they are often tained in full precision on Graphic Processing Units(GPUs).
Why did we shift to GPUs? Our general purpose CPUs are based on Von Neumann digital hardware architecture. This severly limits a neural network’s performance since we cannot perform Multiple and Accumulate operations. Hence, we shifted to GPUs which took advantage of parallelised architecture to perform these MAC operations on a large scale.
But what happens when we shift to smaller devices? How do they differ from the large scale GPUs?
- Power Constraints: Traditionally Neural Networks require massive amount of power and energy while running on GPUs. A GPU on an average consumes 140WTDP. But smaller devices like microcontrollers and microprocessors, for example Raspberry Pi consumes 1-2W of power
- Memory Constraints: Most PCs come with a large memory and RAM; 4/8/16 GB is found on average in most devices. But when we look at edge device they have very less memory.
- Composed of Floating point: Traditionally Neural Networks contain floating point values, but as we move towards low powered devices, it is important to compress these large networks to run on them. One of the effective ways to do so, is to map the higher bit to lower precision bit values aka quantization
Types of Quantization
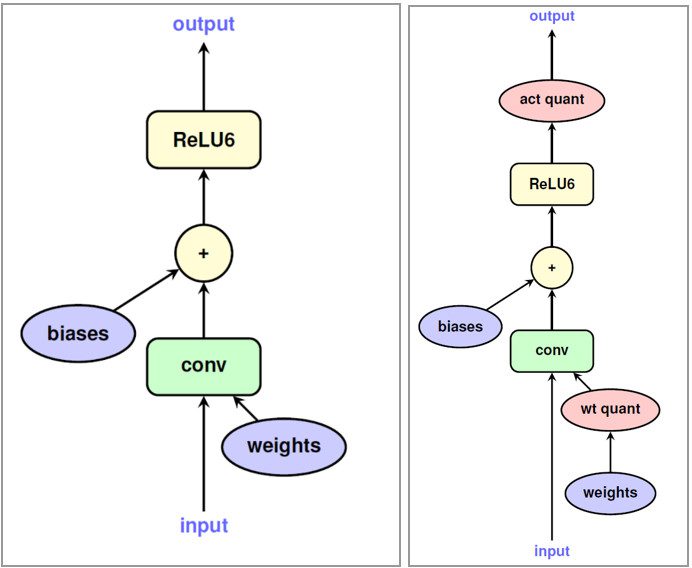
Image Source: KD Nuggets
Weight Quantization:
When we perform weight quantization, we convert all weight values to a lower precision like INT8. This reduces the size of the model. However when we execute the model, we need to convert our weights back to their full precision. So while we do get a lot of memory savings, there is no latency savings and there is a tiny overhead of converting up-converting all weight values.
Weight and Activation Quantization:
Instead of up-converting quantized weights when we perform activation quntization, we keep the activation in low precision and execute the model. By restricting all computation to INT8 precision, we can decrease computation latency as well as model size.
 Knowledge Distillation in Neural Networks
Knowledge Distillation in Neural Networks