Archana
Archana 
Knowledge Distillation
Knowledge Distillation is a process of compressing information from a larger model to a smaller model. The larger model is trained on the dataset. This step is usually performed on high performing GPUs, so that we can make that the model learns all possible representations.
How does this help?
One of the popular steps to model training is to use an ensemble of models on the same data. This is then followed by averaging of predictions across all these models. But as we move towards dealing with larger datasets and adding more data in general, we need to shift to deeper neural networks for solving optimsations. Thus, it becomes computationally expensive to ensemble such models. Instead using a smaller model to understand the data and generalise over it, can benefit the process much better.
So how do we achieve it?
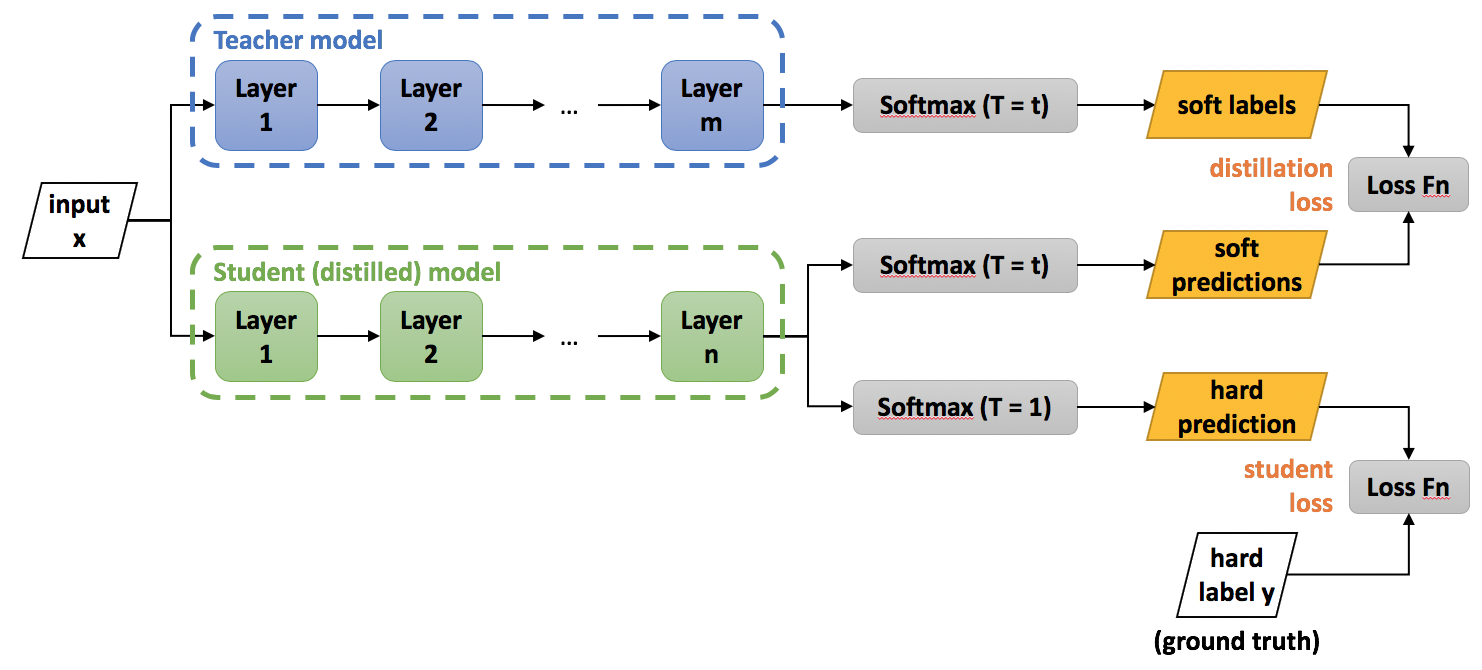
Image Source: Intel Labs
What we understand now is that, we want a larger or teacher model to transfer its ability of generalisation to a student model. Let us go through the process of neural network for simple classification, when a model predicts a class, it assigns a higher probabilities to that class and lower to the rest. This generates soft labels or targets.
These soft labels are then distilled or transferred to the student or smaller model
So when we train the student model on the same data, it is able to converge in a quicker manner and then produce the true labels needed for result.
This student model has the advantage of being trained away from the teacher model, in any environment. This way it will still retain the soft labels, but won’t be dependent on highly computationally devices for training.
Thus making this system ideal for TinyML or Deep Learning in Microcontrollers.
Does this really work?
Now that we have understood the theory, let us look at some interesting results.
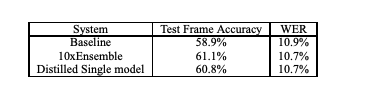
The original paper on Knowledge Distillation covers the experiment on speech recognition. The authors use an ensemble of Deep Neural Networks that are used for Automatic Speech Recognition(ASR). The metrics used to udnerstand the results are Frame accuracy and Word Error Rate.
The interesting takeway is that a single distilled model is able to gain the same accuracy as that 10 times an ensemble system
Ok I am interested where do I start?
Awesome, if we have got you interested, you can check the steps to Knowledge Distillation on Keras
Alternatively, you can use the scaledown package and do it in less than 10 lines of code!
Resources
- Towards Data Science: Knowledge Distillation Simplified
- Neural Network Distiller: Knowledge Distillation
- Research Paper: Distilling the Knowledge in a Neural Network
 We got funded!
We got funded!