 Soham
Soham 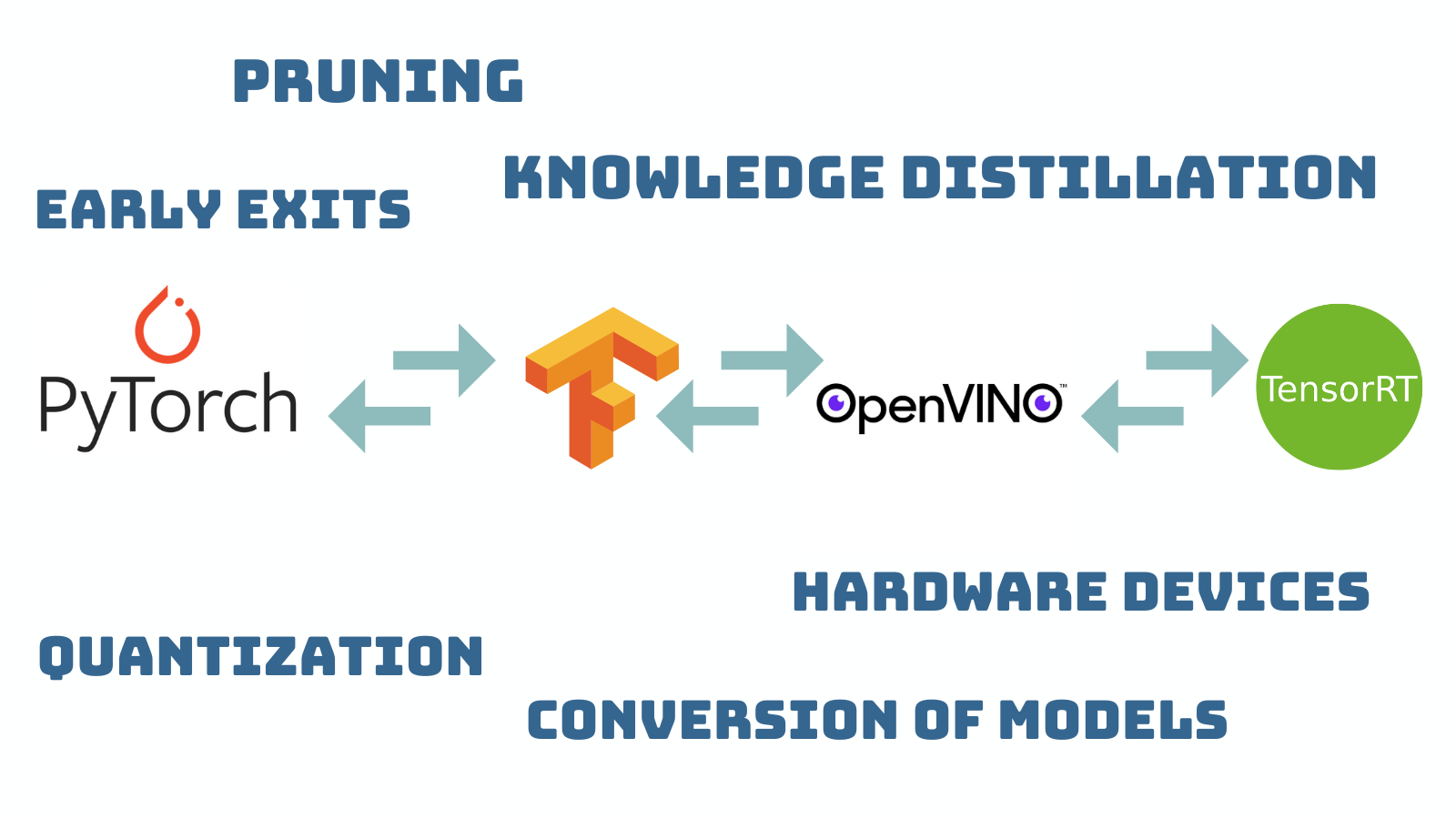
Over the last decade, the popularity of smart connected devices has led to an exponential growth of Internet of Things (IoT) devices. Around the same time, the availability of a vast amount of data and parallel computing using GPUs has also increased the utilization of deep learning and neural networks in the industry
Industry estimates show that the number of IoT devices is expected to increase to more than 20 billion devices by 2025. Moreover, the number of IoT devices will be approximately twice as many as the number of non-IoT devices connected to the internet. Finally, it is projected that by 2030, smart products will make up more than 50% of the total revenue generated by AI products. This shows the importance, value and ubiquity that AI and IoT will have in our lives over the next few years.
While both of these fields were progressing separately, in the last few years, interest has been shown in running deep learning models on IoT devices to reduce latency and to increase system resilience and security. This computing paradigm where networks are run at the place where data is generated (IoT devices) is known as edge computing or TinyML.
TinyML devices are small, meaning that they have less memory and computational power. This means that standard deep learning models which are large, computationally expensive and often require GPUs to execute cannot be deployed on to them. Instead, TinyML models need to occupy less memory and require less operations to execute so that we can get results from them quickly.
Many techniques have been invented to scale down and optimize large models so that they can be deployed to TinyML devices. However, since TinyML is still a niche and nascent field, most of these optimization techniques and algorithms are published as research papers and not accessible to hobbyists or industry professionals. While some algorithms are implemented in a few popular deep learning frameworks, they are not standardized between frameworks or cannot be configured easily. This means that a model trained in a framework like Pytorch, cannot use TFlite’s quantization or interpreter when deploying to a TinyML device.
ScaleDown is an Open-Source Neural Network Optimization framework which aims to reduce the difficulty in optimizing and deploying models to TinyML devices. We do this while providing a framework agnostic API that supports commonly used deep learning frameworks. As new optimization techniques are invented, we study them and add their implementation to our framework so that hobbyists, researchers and industry practitioners can use them in their projects. Finally, at ScaleDown, we believe in progressing the field by doing research, giving free education and training budding hardware and software engineers in TinyML. To that end, we conduct study groups and workshops, publish blogs and are working on two free TinyML books.